System Administrators focus on maintaining and configuring servers, ensuring system stability and security for development environments. Site Reliability Engineers (SREs) blend software engineering and operations to enhance system reliability, automate processes, and improve scalability. In development, SREs prioritize proactive monitoring and incident response, while System Administrators handle routine infrastructure management.
Table of Comparison
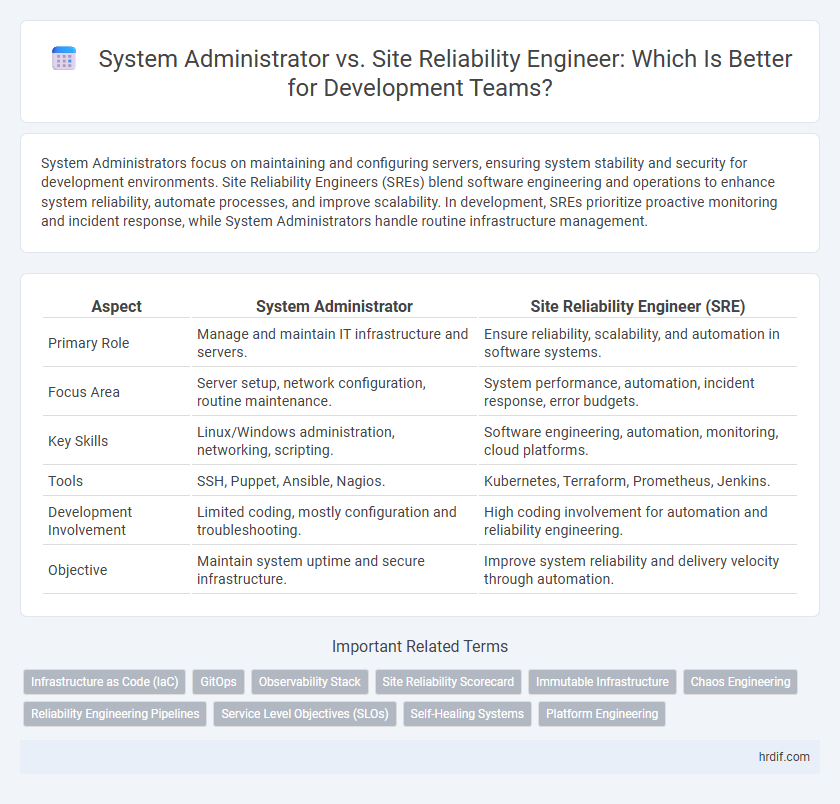
| Aspect | System Administrator | Site Reliability Engineer (SRE) |
|---|---|---|
| Primary Role | Manage and maintain IT infrastructure and servers. | Ensure reliability, scalability, and automation in software systems. |
| Focus Area | Server setup, network configuration, routine maintenance. | System performance, automation, incident response, error budgets. |
| Key Skills | Linux/Windows administration, networking, scripting. | Software engineering, automation, monitoring, cloud platforms. |
| Tools | SSH, Puppet, Ansible, Nagios. | Kubernetes, Terraform, Prometheus, Jenkins. |
| Development Involvement | Limited coding, mostly configuration and troubleshooting. | High coding involvement for automation and reliability engineering. |
| Objective | Maintain system uptime and secure infrastructure. | Improve system reliability and delivery velocity through automation. |
Defining the Roles: System Administrator vs Site Reliability Engineer
System Administrators primarily focus on maintaining and managing IT infrastructure, ensuring servers, networks, and systems run smoothly with minimal downtime. Site Reliability Engineers (SREs) blend software engineering and systems administration to create scalable and automated solutions for reliability and performance in production environments. SREs emphasize proactive monitoring, incident response automation, and continuous improvement, whereas System Administrators handle routine maintenance and direct management of hardware and software resources.
Core Responsibilities in Development Environments
System Administrators focus on managing and maintaining servers, networks, and infrastructure to ensure stable and secure development environments by handling configurations, patch management, and access controls. Site Reliability Engineers (SREs) emphasize automation, monitoring, and reliability of development pipelines and application deployment processes to minimize downtime and improve system scalability. SREs integrate software engineering principles with infrastructure management to optimize performance and streamline continuous integration/continuous delivery (CI/CD) workflows.
Key Skills Required for Each Role
System Administrators require expertise in network configurations, server management, and troubleshooting operating systems, with strong knowledge of scripting languages such as Bash or PowerShell for automation. Site Reliability Engineers (SREs) blend software engineering skills with system administration, emphasizing proficiency in cloud computing, container orchestration tools like Kubernetes, and monitoring systems to ensure high availability and performance. Both roles demand solid knowledge of Linux environments, but SREs focus more on software development, reliability engineering, and infrastructure as code practices.
Tools and Technologies: SysAdmin vs SRE
System Administrators primarily use configuration management tools like Ansible, Puppet, and Chef to maintain server infrastructure, focusing on manual intervention and routine tasks. Site Reliability Engineers leverage advanced automation platforms such as Kubernetes, Prometheus, and Terraform to achieve scalable, resilient systems with continuous monitoring and automated incident response. The SRE role integrates software engineering practices with operations, emphasizing cloud-native tools and real-time system telemetry for proactive reliability management.
Approach to Automation and Infrastructure as Code
System Administrators traditionally manage infrastructure through manual configurations and scripted automation tailored to specific environments, focusing on stability and routine maintenance. Site Reliability Engineers (SREs) emphasize extensive automation using Infrastructure as Code (IaC) tools like Terraform and Ansible to enable scalable, repeatable, and version-controlled infrastructure deployments. SREs integrate development and operations practices by applying software engineering principles to automate infrastructure management, ensuring reliability and rapid iteration in development cycles.
Troubleshooting and Incident Response Comparison
System Administrators primarily handle routine troubleshooting by managing system configurations and performing reactive incident response, ensuring system stability through manual intervention. Site Reliability Engineers (SREs) implement automated monitoring and use data-driven incident response strategies to proactively identify and resolve issues, reducing downtime and improving scalability. SREs emphasize building self-healing systems and real-time alerting, offering a more efficient and systematic approach to incident management compared to traditional system administration.
Impact on Development Workflow and Productivity
System Administrators ensure stable infrastructure and manage server operations, which minimizes downtime and supports smooth development cycles. Site Reliability Engineers (SREs) focus on automating operations, integrating monitoring and performance tuning, which accelerates deployment frequency and reduces incident resolution times. Adopting SRE practices enhances continuous integration and delivery pipelines, significantly improving development workflow efficiency and overall productivity.
Collaboration with Development Teams
System Administrators primarily manage infrastructure and ensure system stability, while Site Reliability Engineers (SREs) focus on automating processes to enhance reliability and scalability within development environments. SREs collaborate closely with development teams by integrating monitoring, incident response, and performance optimization directly into the software development lifecycle. This collaboration reduces downtime and accelerates deployment cycles, promoting continuous integration and continuous delivery (CI/CD) practices.
Career Pathways and Professional Growth Opportunities
System Administrators primarily focus on maintaining and configuring infrastructure, acquiring deep knowledge in network management, system security, and hardware troubleshooting, which builds foundational IT skills suitable for transitioning into specialized roles. Site Reliability Engineers (SREs) combine software engineering and systems management to enhance system reliability and scalability, offering advanced career pathways in DevOps, cloud architecture, and automation engineering. Professional growth for SREs often involves mastering coding, CI/CD pipelines, and monitoring tools, positioning them for leadership roles in development operations and cloud infrastructure management.
Deciding Between System Administrator and SRE for Your Development Team
Choosing between a System Administrator and a Site Reliability Engineer (SRE) depends on your development team's focus on infrastructure management versus scalability and automation. System Administrators excel in managing servers, networks, and basic IT operations, while SREs specialize in applying software engineering principles to ensure system reliability, performance, and continuous integration/continuous deployment (CI/CD) pipelines. Prioritizing an SRE role often benefits teams aiming for robust automation, proactive monitoring, and rapid incident response within complex, cloud-native environments.
Related Important Terms
Infrastructure as Code (IaC)
System Administrators traditionally manage physical and virtual infrastructure through manual configuration, whereas Site Reliability Engineers (SREs) leverage Infrastructure as Code (IaC) to automate provisioning, scaling, and maintenance processes, improving system reliability and deployment speed. IaC tools like Terraform, Ansible, and AWS CloudFormation empower SREs to create repeatable, scalable infrastructure environments that align development and operations teams for continuous delivery and improved uptime.
GitOps
System Administrators traditionally manage infrastructure and operations, while Site Reliability Engineers (SREs) emphasize automation and reliability through software engineering principles. In GitOps-driven development environments, SREs leverage version-controlled declarative configurations and continuous integration pipelines to ensure system stability and rapid incident response, surpassing conventional administrative roles.
Observability Stack
System Administrators primarily manage and maintain the infrastructure that supports the observability stack, ensuring system stability and availability, while Site Reliability Engineers (SREs) design and implement scalable monitoring, alerting, and logging solutions to proactively detect and resolve issues in development environments. SREs leverage tools such as Prometheus, Grafana, and ELK Stack to enhance observability, enabling faster incident response and continuous reliability improvements.
Site Reliability Scorecard
Site Reliability Engineers (SREs) use a detailed Site Reliability Scorecard to measure system health, focusing on key metrics such as service uptime, error rates, and latency, which guides continuous improvement in development environments. Unlike traditional System Administrators, SREs emphasize automated incident response and reliability engineering practices to maintain scalable and resilient software infrastructure.
Immutable Infrastructure
Site Reliability Engineers (SREs) emphasize Immutable Infrastructure to enhance scalability and reduce configuration drift by deploying automated, version-controlled systems, whereas System Administrators traditionally manage mutable environments with manual updates and patches. Immutable Infrastructure enables consistent development workflows, minimizes downtime, and accelerates continuous integration and delivery pipelines vital for modern software development.
Chaos Engineering
Site Reliability Engineers (SREs) integrate Chaos Engineering principles to proactively identify system vulnerabilities and improve resilience through controlled failure simulations, enhancing overall application stability. In contrast, System Administrators primarily focus on routine maintenance, configuration management, and reactive troubleshooting without emphasizing proactive resilience testing in development environments.
Reliability Engineering Pipelines
Site Reliability Engineers (SREs) focus on automating and scaling reliability engineering pipelines using tools like Jenkins, Prometheus, and Kubernetes to enhance system uptime and performance. System Administrators typically manage infrastructure and perform manual maintenance tasks, whereas SREs implement proactive monitoring, incident response, and continuous improvement practices within development workflows.
Service Level Objectives (SLOs)
System Administrators typically manage infrastructure and ensure system uptime, but Site Reliability Engineers (SREs) are specifically focused on defining, monitoring, and achieving Service Level Objectives (SLOs) to enhance development reliability and performance. SREs apply software engineering principles to automate incident response and capacity planning, aligning SLOs closely with customer experience and development lifecycle needs.
Self-Healing Systems
Site Reliability Engineers (SREs) design and implement self-healing systems that automate responses to failures, enhancing uptime and reducing manual intervention. System Administrators primarily manage infrastructure and troubleshoot issues but typically lack the programming focus required to develop automated self-recovery mechanisms essential for modern development environments.
Platform Engineering
System Administrators focus on managing and maintaining infrastructure, handling routine tasks like server provisioning, network configuration, and system monitoring, while Site Reliability Engineers (SREs) emphasize automating operations, ensuring scalability, and enhancing platform reliability through software engineering practices. In platform engineering, SREs integrate development and operations by building self-service tools, optimizing CI/CD pipelines, and implementing robust monitoring solutions to improve application performance and developer productivity.
System Administrator vs Site Reliability Engineer for Development. Infographic